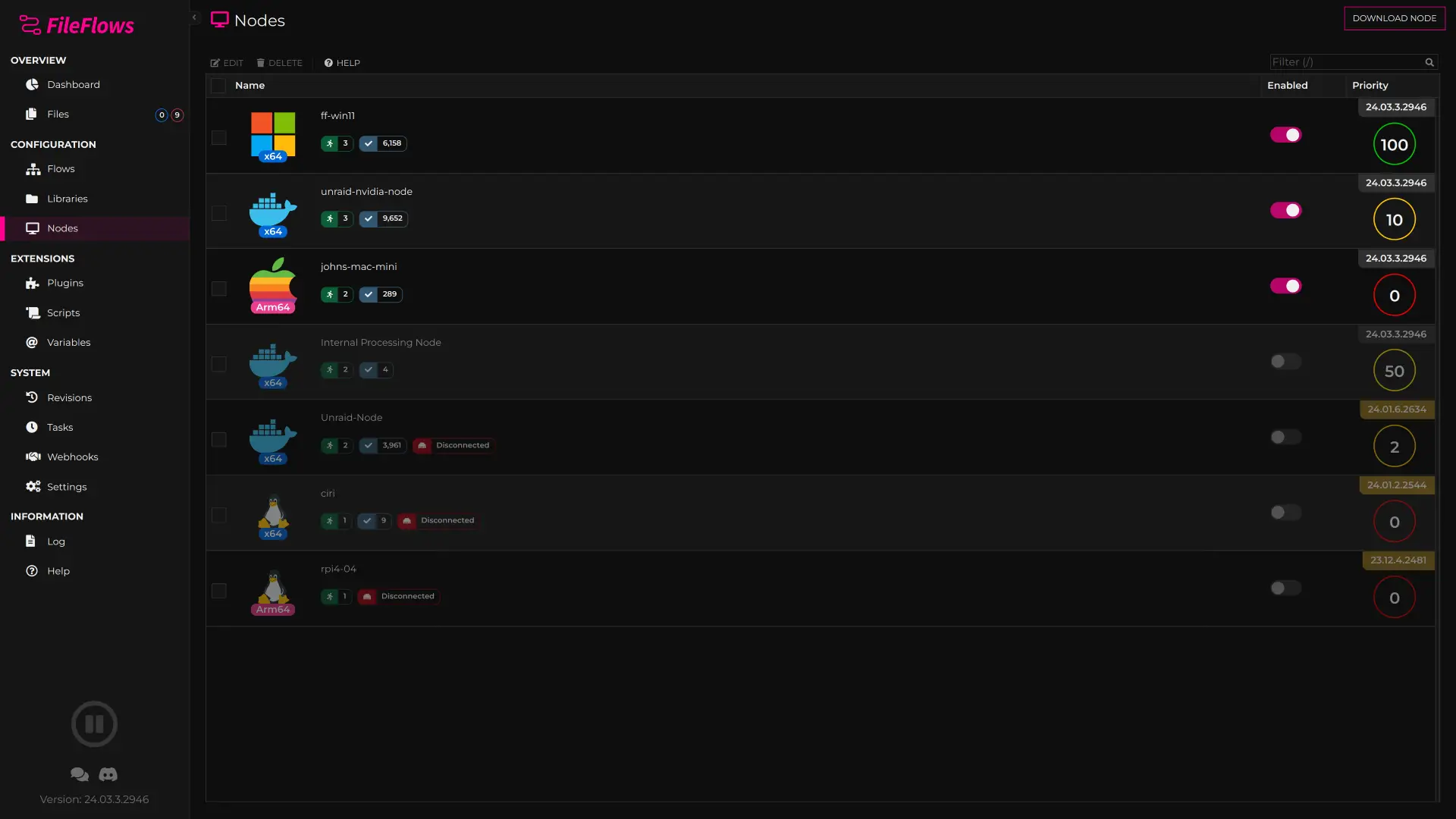
Nodes
Processing Nodes, or simply Nodes, are instances that actually execute a flow and process the library files.
FileFlows Server (the main application) has an in-built processing node and this is all that is needed for FileFlows to work. However, if you want to split the workload onto more machines or you don't want the server doing the processing; you can install additional nodes on other machines.
For example, install FileFlows as an unRAID application, and have a FileFlows node installed on a much more powerful Windows machine. You could have the unRAID process 1 file at a time and you could have the Windows machine process 3 additional files. Or you could farm it out and have 1000 nodes processing 1000 files each at a time.
Settings
General
- Name
- The display name of the Node
- Address
- The IP or hostname address of the node
- Enabled
- If the node is enabled or not and can process files
- Flow Runners
- The number of simultaneous files this node can process
- Priority
- The higher the value the greater the priority. This number will be reduced by the executing files on this node. So if set to 50 and 2 files are running, the calculated priority when requesting a new file will be 48. This allows you to have two nodes at 51 and 50, so the 51 is the prefered node, but they will be load balanced, just the 51 will always start first.
- Temp Directory
- The directory on the node to store temporary files created by the Flow Runner
- Pre-Execute Script
- See Pre-Execute Script for more information.
Schedule
This allows you to set a processing schedule for a node. This schedule is when a file is allowed to start processing. If a file start processing 1 minute before the schedule ends, that file could still be processing outside of the schedule, but no additional files will be processed.
Mappings
This allows you to map variables and directories from the Server to the Node. You need to map any path used in the Flow or Libraries to locally available paths on the node. You also need to map any variables used in FileFlows to the Node, for example map FFmpeg from the server to where you installed FFmpeg locally on the node.
Processing
This allows you to set conditions on what files this node can process
- All Libraries
- Whether or not this node can process all libraries in FileFlows
- Libraries
- If All Libraries is unchecked, specify which libraries this node can process
- Max File Size
- Set to 0 to have no max
- The file size limit this node can process.
- For example, you may wish to limit a Raspberry Pi node so it can only process smaller files due to it's memory constraints.
- File Check Interval
- How often to check for a new file to processing in the processing nodes.
- Set to 0 to use the system value.
- Processing Order
- Requires
Processing Orderlicense to use - When not default, this node will ignore processing order on libraries and use this order to determine the next file to process.
- Requires
Advanced
- Change Owner
- When checked the node will change the owner of any newly created files to the PGID and PUID defined in the environmental values.
- If these environmental variables are not set the owner will be changed to 'users:nobody'.
- Set Permissions
- When checked file permissions will be set on any newly created files
- File Permissions
- Only available for Linux hosts, will default to 644. All newly created files will have these permissions applied to them
- Folder Permissions
- Only available for Linux hosts, will default to 775. All newly created folders will have these permissions applied to them
Configuration
When the node runs it stores a local copy of the FileFlows configuration (Flows, Libraries, Plugin settings etc) which is used for processing.
By default this configuration is stored as an encrypted file on the system.
However, if there is an issue with this you can disable the configuration by using the environmental variable
FF_NO_ENCRYPT = 1
The configuration will be cleared whenever the node is restarted and by default a new random encryption key will be used so there is no way to view the contents of this file.
However you can specify a custom encryption key to be used by using the environmental variable
FF_ENCRYPT = my-custom-key-whatever-you-like
Both these variables will be read when the FileFlows node is started, so any changes will require the node to be restarted.